Semantic Vector Tools
Introduction
The "Semantic Vector Tools" are the set of SemSim, SemTag, SemNull, and SemCluster (linked here). This page aims to explain the basic idea, what the tools do, and how to use them.
These functions all use the word2vec methodology, with the Gensim and NLTK toolboxes. What word2vec gives is a mathematical representation of the meaning of a word as a vector, with a dimension in the order of 300: a "word embedding" or "semantic vector".
Illustrations of semantic vectors:
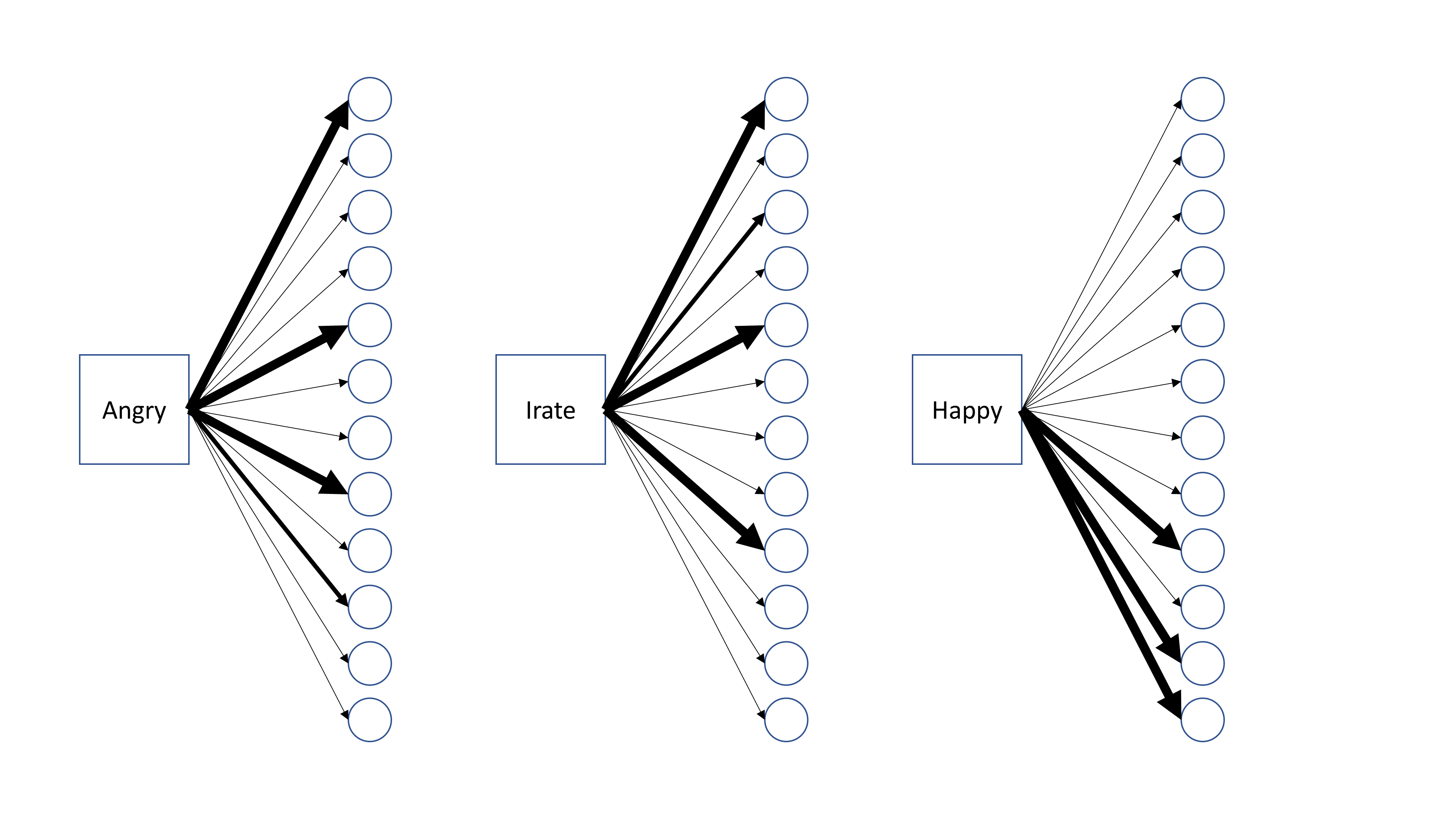
The meaning of a given word is encoded in its pattern of weights with a layer of network nodes. Each word in a vocabulary is a different input node with its own set of connections. Words with similiar meanings have similar patterns of weights; in this picture, "angry" and "irate" are similar to each other, but different from "happy".
Such vectors are created by training a neural network to predict, for each word in a vocabulary, which words occur around it in some preferably very large corpus of text. The connections from input nodes, one for each individual word, to the hidden layer of the network are subsequently extracted to get the semantic vectors for each word. (The training can be done in different ways, but this explains what I think is the most intuitive method.) The relatively low dimension of the hidden layer forces the network to learn informative patterns, based on whether words tend to be interchangeable relative to their context. The interesting consequences is that vector algebra can be applied to this representation of meaning. Distance measures between word vectors are a natural way to represent their similarity, vectors can be reversed to get opposite meanings, and vectors can be added to and subtracted from each other to construct derived concepts.
Whether this translation into vector algebra "works" in any given sense is, in principle, an empirical question. Studies have, in fact, connected cognitive and social relationships to models. For instance, Caliskan et al. (2017) demonstrated the existence of real-world stereotypes in word embeddings - theoretically interesting and a warning against irresponsible applications; and Lynott et al. (2012) showed connections between model-based similarities and behavioural biases. There are a lot of potential theoretical and practical applications; and, perhaps attractively, the model is simple enough not to have any undue mystique.
I found the idea fascinating, especially as a way to flesh out the concept of "automatic associations". The scripts I wrote as part of some psychological studies on this were open source, but a bunch of homebrew Python scripts still aren't very accessible. So I've now been converting them into the Semantic Vector Tools web apps: SemSim for basic similarity scores, SemTag for tagging text, and SemNull for statistical significance testing of associations.
SemSim
SemSim provides the basic semantic similarity score. It takes three inputs: a list of target words, a "positive" set of words and a "negative" set of words. For each target word, the average similarity between the target word and the positive words is calculated, and the average similarity between the target word and the negative words is subtracted from that. Similarity is calculated as the dot product between the word embedding vectors.
If the target word is "more like" the set of positive words than the set of negative words, it will have a positive similarity score. (In advance, the size of the score can be statistically tested using SimNull.) Note that "positive" and "negative" don't refer to good versus bad here, just to what will be subtracted from what.
Illustrations of input and output:


These inputs test whether particular emotions are good or bad. As expected, the words "angry", "furious" and"depressed" are more related to the negative set, while "satisfied" and "joyous" are more related to the positive set (in this case, the positive and negative sets are also positive and negative in meaning).
So what could one do with that? What I used the method for was a study involving an Implicit Association Test (IAT) variant (Gladwin, 2022). It turned out that the model-based semantic similarity between words and the word sets of interfering categories was associated with incongruence effects on reaction time. That is - there's at least some connection between this linguistic model and a psychological construct, namely, automatic "unconscious" associations (for further details and theoretical and methodological discussion, see the paper).
SemTag
SemTag is based on EmpathyBot, a Twitter-bot practice project that pretended to tell people their emotions. The current tool takes a text, split into linebreak-separated paragraphs, and assigns a set of words to the text and a word to each paragraph. The assigned words are based on the highest semantic similarity of words in a paragraph and a given set of potential tag words. In memory of EmpathyBot, the default tag words are emotion-words, but a different set of tags can be specified.
The similarity scores are provided along with the tags. This allows the fittingness of a given tag to be evaluated, relative to other tagged paragraphs.
If a tag-word itself is found in the text, then it will trivially be recognized. However, more subtle semantic associations can also be detected. For instance, "funeral" could be tagged by "grieving", and "party" by "celebrating". The algorithm is simple but does try to deal with basic negations.
Illustrations of input and output:


So, the paragraphs (in this case, single sentences) receive fitting selections from the tags. Some sentences contain the tag itself, which is correctly recovered; other show a more subtle tagging, for example "celebration" for the sentence about a birthday party and "grieving" for the sentence about a funeral. The three highest-matching tags over the whole text are also given.
This could potentially be helpful to provide a quick-and-dirty analysis of text data, given appropriate data and tag selection. The output from SemTag could be provided to SemSim for a multi-stage analysis, e.g., from emotion-detection in SemTag to a valence filter using SemSim, resulting in positive-versus-negative scores for each paragraph.
SemNull
SemNull provides a statistical test of (relative) semantic similarity scores. The basic idea is simply to use random sampling from the model vocabulary to generate a null hypothesis distribution of similarity scores (as has been done in the scientific literature, e.g., Caliskan et al., 2017). The way SemNull does this is via a template sentence and a part-of-speech tag, which aims to restrict the null distribution to relatively relevant words.
The input to SemNull is set of target words, positive words, and negative words, as in SemSim; or already-known similarity scores that could have been taken from SemSim or SemTag. The target word will be randomized to get the null distribution, and hence the p-value of the observed similarity of the original pair.
Random words are only selected if they fit within the template sentence and part-of-speech tag. The template sentence and specified grammatical form should match the test word. E.g., if the target is "angry", then the template sentence could be "I am $", where the $-sign represents the word to randomize, and the part-of-speech tag would be an adjective.
Illustrations of input and output:


In this illustration, each of the drinks beer, coffee, and wine is being tested on its associations with word sets reflecting drunkenness versus alertness. The template sentence selects for adjectives. The results show a significant (for p below .05) association for beer only.
This method was used to explore whether biophilic connections exist in language usage (Gladwin, Markwell & Panno, 2022). If so, these semantic associations could potentially underpin positive psychological responses to nature. It was also interesting in itself to see whether models could have positive "green" biases in addition to social stereotypes.
SemCluster
SemCluster takes as input a comma-separated list of words, and divides them up into subsets with similar meanings. This uses PCA for an initial dimension reduction and subsequenly uses K-means clustering on the components.
Illustrations of input and output:


In this illustration, the word list has animals, buildings, and emotions. These are separated into clusters.